Neuronale Netze
Ein Multi-Layer Perzeptron (MLP) mit einer Vielzahl von künstlichen Neuronen, die in mehreren Schichten organisiert sind, bezeichnet man als (künstliches) Neuronales Netz (KNN / ANN).
Die grundlegende Architektur besteht aus drei Arten von Schichten (Layers):
- Input Layer (Eingabeschicht)
- Hidden Layer(s) (Verborgene Schichten)
- Output Layer (Ausgabeschicht)
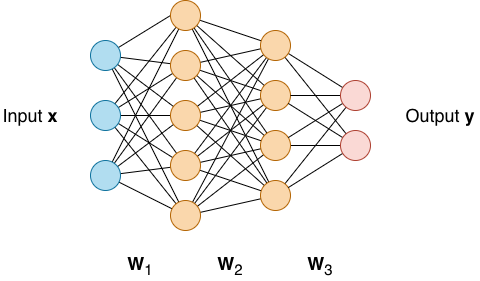
Im Zusammenhang mit LLM ist of von Parametern die Rede. Jede Linie in dieser Graphik ist einen Parameter ().